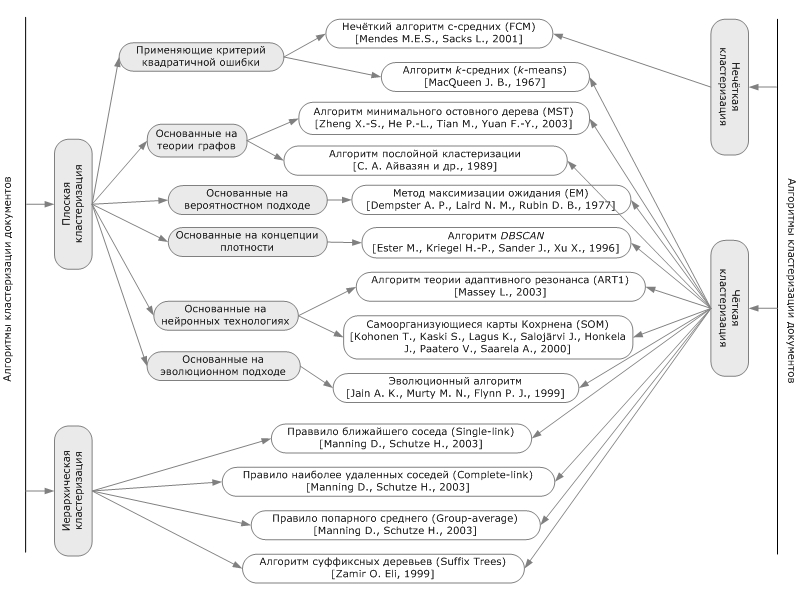
С чего начать студенту, заинтересовавшемуся вопросами информационного поиска
Введение
Постановка задачи информационного поиска
Информационный поиск (Information Retrieval) - это процесс поиска в большой коллекции некоторого неструктурированного материала (документа), удовлетворяющего информационные потребности.
Маннинг К. Д., Рагхаван П., Шютце Х.
Введение в информационный поиск.
Поисковая система в общем виде представлена на рис. 1. В зависимости от типа задачи пользователь формирует различные запросы и обращается к различным поисковым механизмам. Однако общим для всех задач является то, что:
- пользователь формирует запрос (A) естественным для него (человека) способом;
- пользователь желает искать среди объектов (C), представленных в традиционном для него виде;
- машина получая запрос пользователя, преобразовывает его к формальному описанию (B), затем ищет среди коллекции документов, заранее преобразованных к формальному виду (D), наиболее близкие к запросу пользователя (релевантные) документы.
.jpg)
Рис. 1. Поисковая система в общем виде
Под формальным описанием исходных объектов поиска, или образами объектов, будем понимать представление объекта (документа, запроса) в виде списка его признаков, например, слов или словосочетаний, снабжённого информацией о значимости (весе) каждого признака для содержания (тематики) конкретного документа. Процесс предварительной обработки документов, нацеленный на формирование образов документов, часто называют индексацией коллекции документов.
Представим, что имеется множество документов D размерностью ND. После выделения признаков из каждого документа получаем множество признаков P размерностью NP. Множество признаков содержит все признаки, встречающиеся хотя бы в одном из документов. Тогда получаем разреженную матрицу «документ-признак»:
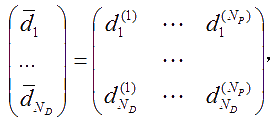
строками которой являются образы документов —di, для каждого из которых известен вес каждого признака (вес равен нулю в случае отсутствия некоторого признака в некотором документе). Далее поисковая задача сводится к применению некоторого математического метода для анализа матрицы «документ-признак» и принятия решения о релевантность того или иного образа документа, а следовательно и самого документа. Это одна из поисковых моделей – векторная модель. Существуют и другие модели (подробнее - в основной литературе о методах и проблемах информационного поиска).
Важной проблемой является оценка результатов работы поисковой машины (IR Evaluation). В настоящее время известен ряд метрик, позволяющих получить количественную оценку качества поиска. Их можно разделить на две группы: внешние (а) и внутренние (б) метрики.
Внешние метрики – требуется сравнить результат поиска, выполненный автоматически, с результатом выполненным экспертами, т. е. необходимо наличие «эталонного» поискового результата, составленного человеком. Ярким примером таких метрик являются всем известные полнота (recall) и точность (precision). Интерпретация этих метрик меняется в зависимости от типа решаемой задачи, однако, общий смысл остаётся неизменным. Его проще всего раскрыть на примере задачи классического поиска. Так, полнота – это количество релевантных (соответствующих запросу) документов в ответе поисковой машины по отношению к общему количеству релевантных документов в коллекции документов, а точность – это количество релевантных документов в ответе поисковой системы по отношению к общему количеству документов в ответе системы.
Внутренние метрики – анализируют результат работы поисковой системы без привлечения внешней информации, т. е. не требуется «эталонный» результат поиска. Например, анализ средних межкластерного и внутрикластерного расстояний в задаче кластеризации документов.
Таким образом получаем, что основными направлениями исследований являются следующие:
- как и какие выявить признаки исходных объектов (а также и объектов-запросов), чтобы они наилучшим образом отображали смысл объектов, который видит в них человек (пользователь);
- как эффективно сравнить формальные описания заданных объектов и объектов, среди которых осуществляется поиск;
- как оценить, хорошо или плохо был выполнен поиск: удовлетворён ли пользователь результатами поиска, т. е. какие формальные критерии использовать, чтобы вычислить формальные характеристики качества поиска, совпадающие с мнением большинства людей (пользователей системы);
- как эффективно организовать хранение поисковой информации и обеспечить быстрый и надежный доступ поисковым машинам к данной информации (Структуры данных для поисковых систем).